' fill='none' stroke='%23304560' stroke-miterlimit='10' stroke-width='2'/%3e%3c/svg%3e)

A lunchtime conversation: technical, biological and pseudo-replication
Dr. Vanessa Cave
01 December 2021
What do you talk about over a workday lockdown lunch with a partner who’s also a statistician? Well, today in my home it was the three flavours of replication: technical, biological (or “true”) and pseudo replication. Why was this a topic of interest? Because knowing what type of replication you have not only impacts how your data should be analysed but also the conclusions that can be drawn. Unfortunately, this is not always well understood.
So, let’s examine the different types of replication in turn:
Technical replication: Understanding variability
What? Technical replicates are repeated measurements taken on the same sample.
Why? Technical replicates are used to understand the noise (i.e., variability) associated with a protocol, procedure or piece of equipment.
Example? A blood diagnostic company running repeated measurements on a patient’s sample to study the reproducibility of their testing procedure.
Therefore? If the technical replicates are highly variable the observed effects will be difficult to distinguish from the background noise.
Exploring biological replication
What? Biological replicates are independent measurements taken on distinct biological samples (ideally a random sample from the studied population).
Why? Biological replicates are used to understand the biological variation in the population under study.
Example? In a clinical trial, blood measurements are collected on many patients to understand the effect of a new drug treatment in the studied population.

Therefore? Biological replication allows us to generalize our results to the wider population of interest.
Decoding pseudo-replication: The pitfalls of treating data as independent
What? Pseudo-replication occurs when data are treated as independent when they are not.
Why? Pseudo-replication arises due to errors in the planning or execution stage of an experiment, or during the statistical analyses.
Example? A clinical trial in which patients have been recruited from several medical centres and the treatments (either the control or new drug) are applied at the medical centre level but this structure hasn’t been accounted for in the analysis.
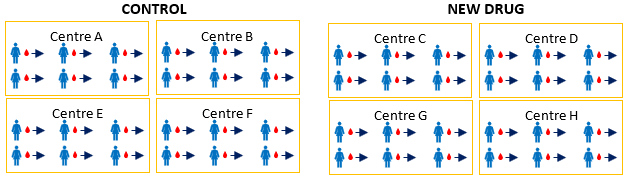
Therefore? If not correctly accounted for in the analysis, pseudo-replication will lead to invalid inferences.
You can learn more about pseudo-replication and how to identify and deal with it in Salvador Gezan’s excellent blog, Dealing with pseudo-replication in linear mixed models.
About the author
Dr Vanessa Cave is an applied statistician interested in the application of statistics to the biosciences, in particular agriculture and ecology, and is a developer of the Genstat statistical software package. She has over 15 years of experience collaborating with scientists, using statistics to solve real-world problems. Vanessa provides expertise on experiment and survey design, data collection and management, statistical analysis, and the interpretation of statistical findings. Her interests include statistical consultancy, mixed models, multivariate methods, statistical ecology, statistical graphics and data visualisation, and the statistical challenges related to digital agriculture.
Vanessa is currently President of the Australasian Region of the International Biometric Society, past-President of the New Zealand Statistical Association, an Associate Editor for the Agronomy Journal, on the Editorial Board of The New Zealand Veterinary Journal and an honorary academic at the University of Auckland. She has a PhD in statistics from the University of St Andrew.
Popular



Related Reads